
The exponential rise in the popularity of artificial intelligence in general and large language models in particular has forced businesses to rethink their cybersecurity approaches. Cybersecurity professionals are also using these tools to improve their cybersecurity. The growing number of AI based attacks is a testament that cyber criminals are using AI tools to boost the effectiveness of their malicious campaigns.
So, how can businesses combat these emerging threats in such a situation? By knowing about them and understanding the risk each threat poses to their business. The Open Worldwide Application Security Project has recently released a list of top ten large language model vulnerabilities and the impact it could have on your business.
They have also highlighted how prevalent each threat is and how easily these vulnerabilities can be exploited by cybercriminals. Continue reading to find out more. In this article, you will learn about ten most dangerous large language model vulnerabilities you can’t afford to ignore.
- 10 Most Dangerous Large Language Model Vulnerabilities According To OWASP
- 1. Prompt Injection
- 2. Malicious Code Execution
- 3. Server Side Request Forgery Vulnerabilities
- 4. Poor Access Controls
- 5. Inappropriate Error Handling
- 6. Training Data Poisoning
- 7. Lack of AI Alignment
- 8. Neglecting Sandboxing
- 9. Data Leakage
- 10. AI Content Dependency
- Conclusion:
10 Most Dangerous Large Language Model Vulnerabilities According To OWASP
Here are the top ten large language model vulnerabilities according to OWASP.
1. Prompt Injection
Prompt injection involves manipulating the input or context provided to an LLM, leading to undesired or malicious behavior. This vulnerability can be exploited to generate biased or inappropriate responses or even coerce the model into revealing sensitive information. Preventive measures include rigorous input validation, sanitization, and contextual filtering to ensure the integrity and appropriateness of prompts.

2. Malicious Code Execution
Unsanctioned execution of code within an LLM can have severe consequences, such as unauthorized access, privilege escalation, or the execution of arbitrary commands. Mitigating this vulnerability requires robust input validation, strict access controls, and the use of sandboxed execution environments to restrict code execution within predefined boundaries.
3. Server Side Request Forgery Vulnerabilities
Server-Side Request Forgery (SSRF) vulnerabilities occur when an LLM can be tricked into making unintended network requests on behalf of an attacker. This can enable unauthorized access to internal systems, data exfiltration, or even remote code execution. Protecting against server side request forgery vulnerabilities involves input validation, restricting network access, and implementing appropriate network-level security controls.
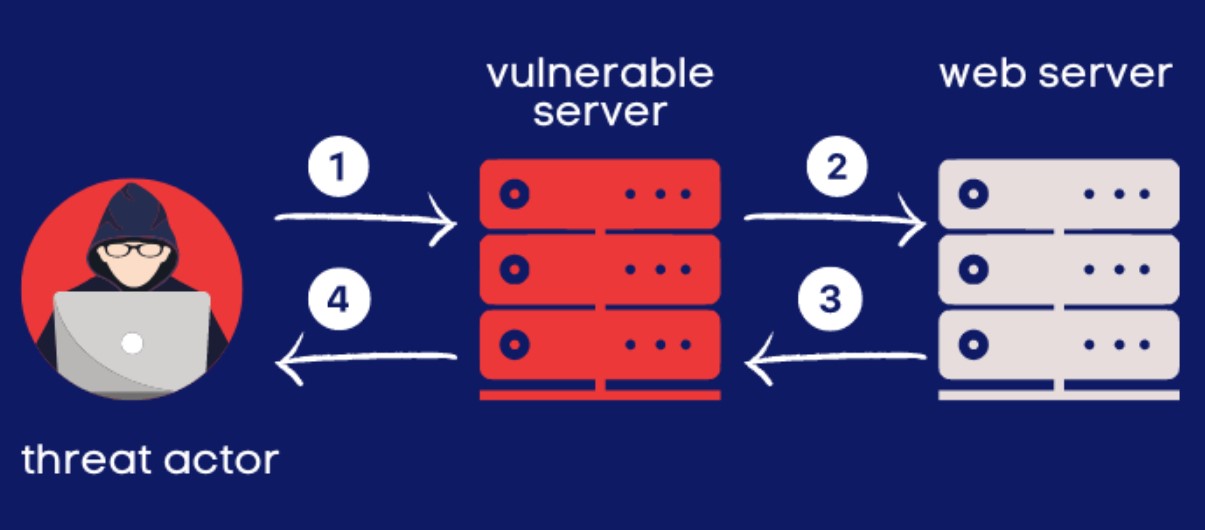
4. Poor Access Controls
Inadequate access controls can result in unauthorized users gaining access to LLMs or the data they process. Proper authentication mechanisms, role-based access controls, and data encryption techniques are vital to ensure only authorized entities can interact with LLMs and sensitive data. Regular audits and security assessments can also help identify and address access control gaps.
5. Inappropriate Error Handling
Weak error handling mechanisms can inadvertently expose sensitive information or provide attackers with valuable insights into an LLM’s internal workings. Robust error handling practices, such as generic error messages, log sanitization, and appropriate exception handling, are essential to prevent information leakage and protect the system’s integrity.
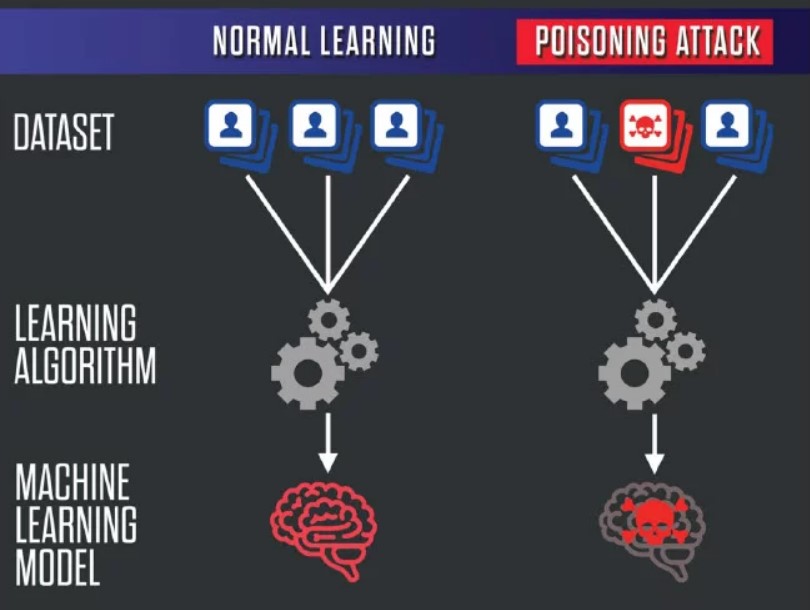
6. Training Data Poisoning
Training data poisoning involves manipulating the data used to train an LLM to introduce biases, malicious intent, or adversarial behavior. Vigilant data validation, diversity in training data sources, and adversarial testing techniques can help detect and mitigate training data poisoning, ensuring LLMs learn from diverse and reliable sources.
7. Lack of AI Alignment
AI alignment refers to the goal of aligning an LLM’s behavior with human values and objectives. If not properly aligned, LLMs may generate outputs that conflict with ethical, legal, or moral standards. Ensuring AI alignment involves careful design choices, transparency in model training, continual monitoring, and iterative improvements to align AI behavior with societal expectations.
8. Neglecting Sandboxing
Sandboxing refers to the isolation of LLMs within secure environments to minimize the impact of potential security breaches. Neglecting sandboxing can allow attackers to exploit vulnerabilities within the LLM and compromise the entire system. Implementing robust sandboxing techniques, such as containerization and virtualization, is crucial to limit the attack surface and minimize potential cybersecurity risks.

9. Data Leakage
Data leakage involves the unintended disclosure or unauthorized access to sensitive information processed or generated by LLMs.To mitigate data leakage vulnerabilities, several measures should be implemented. First, data classification and encryption techniques should be employed to protect sensitive information. Access controls should be implemented at various levels, including data storage, processing, and transmission. Additionally, regular audits and monitoring of data access and usage can help identify and address any potential data leakage incidents promptly.
10. AI Content Dependency
LLMs heavily rely on the data they are trained on, and their responses are influenced by the content they have been exposed to during training. This creates a vulnerability where biased or inappropriate content can result in biased or objectionable outputs. To address this, it is crucial to ensure diverse and representative training data, along with ongoing monitoring and evaluation of the model’s outputs for bias and ethical concerns. Regular updates to the training data can help mitigate content dependency vulnerabilities and promote fairness and inclusivity.
Conclusion:
As large language models continue to advance, it is imperative to proactively address the vulnerabilities that accompany their immense capabilities. By understanding and actively mitigating prompt injection, unauthorized code execution, server-side request forgery vulnerabilities, poor access controls, inappropriate error handling, training data poisoning, lack of AI alignment, neglecting sandboxing, data leakage, and AI content dependency, we can foster the responsible development and deployment of LLMs.
The key to safeguarding against these vulnerabilities lies in implementing robust security practices at multiple layers, including input validation, access controls, error handling, data validation, and continuous monitoring. Collaboration between researchers, developers, and security experts is vital to stay ahead of emerging threats and maintain the trust and reliability of large language models in the future. By mitigating these vulnerabilities, we can ensure that LLMs remain powerful tools for innovation while prioritizing security, privacy, and ethical considerations.
Which of these vulnerabilities is most dangerous in your opinion? Share it with us in the comments section below.



Add comment